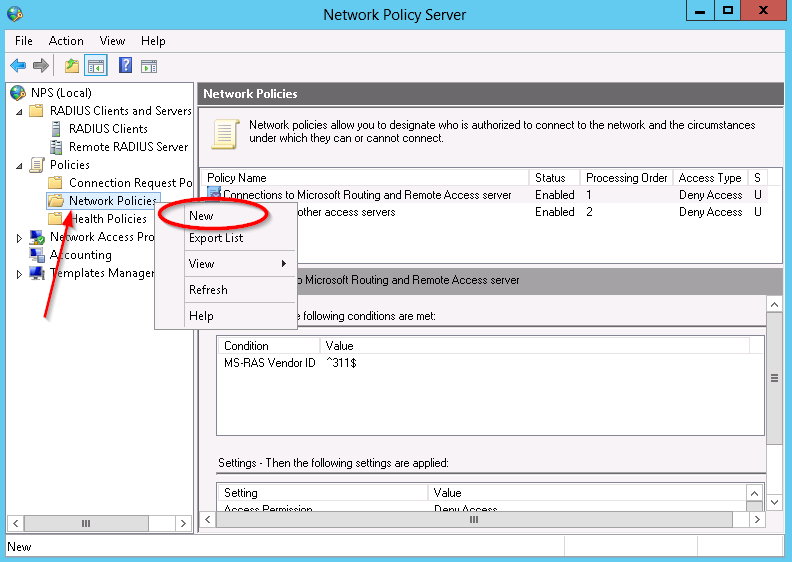
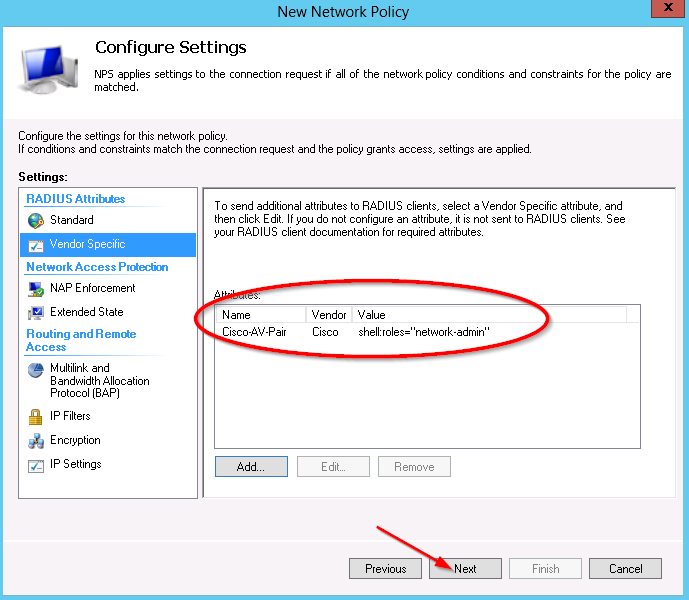
To configure an MST region:
Enter system view and use the command
system-view
Enter MST region view and use the command
stp region-configuration
Configure the MST region name and use the command
region-name name
NOTE: Optional. The MST region name is the MAC address by default.
Configure the VLAN-toinstance mapping table and use the command:
Configure the MSTP revision level of the MST region and use the command
revision-level level
Display the MST region configurations that are not activated yet and use the command
check region-configuration
Activate MST region configuration manually and use the command
active region-configuration
Display the activated configuration information of the MST region and use the command
display stp region-configuration [ | { begin | exclude | include } regular-expression ]
Two or more MSTP-enabled devices belong to the same MST region only if they are configured to have the same format selector (0 by default, not configurable), MST region name, the same VLAN-to-instance mapping entries in the MST region and the same MST region revision level, and they are interconnected via a physical link.
The configuration of MST region–related parameters, especially the VLAN-to-instance mapping table, will cause MSTP to launch a new spanning tree calculation process, which may result in network topology instability. To reduce the possibility of topology instability caused by configuration, MSTP does not immediately launch a new spanning tree calculation process when processing MST region–related configurations; instead, such configurations takes effect only after activating the MST region–related parameters by using the active region-configuration command, or enable MSTP by using the stp enable command in the case that MSTP is disabled.
MSTP can determine the root bridge of a spanning tree through MSTP calculation. Also, there is an option of specifying the current device as the root bridge or a secondary root bridge using the commands provided by the system.
NOTE:
- A device has independent roles in different MSTIs. It can act as the root bridge or a secondary root bridge of one MSTI and being the root bridge or a secondary root bridge of another MSTI. However, the same device cannot be the root bridge and a secondary root bridge in the same MSTI at the same time.
- There is only one root bridge in effect in a spanning tree instance. If two or more devices have been designated to be root bridges of the same spanning tree instance, MSTP selects the device with the lowest MAC address as the root bridge.
- When the root bridge of an instance fails or is shut down, the secondary root bridge (if specified one) can take over the role of the primary root bridge. However, if specified a new primary root bridge for the instance then, the secondary root bridge will not become the root bridge. If the user has specified multiple secondary root bridges for an instance, when the root bridge fails, MSTP will select the secondary root bridge with the lowest MAC address as the new root bridge.
Configuring the current device as the root bridge of a specific spanning tree
To configure the current device as the root bridge of a specific spanning tree follow the steps given below:
Enter system view and use the command
system-view
Configure the current device as the root bridge of a specific spanning tree and use the command
stp [ instance instance-id ] root primary
Configuring the current device as a secondary root bridge of a specific spanning tree
To configure the current device as a secondary root bridge of a specific spanning tree follow the steps given below:
Enter system view and use the command
system-view
Configure the current device as a secondary root bridge of a specific spanning tree
stp [ instance instance-id ] root secondary
After specifying the current device as the root bridge or a secondary root bridge, the user cannot change the priority of the device. The user can also configure the current device as the root bridge by setting the priority of the device to 0.
MSTP and RSTP are mutually compatible, and can recognize each other’s protocol packets. However, STP is unable to recognize MSTP packets. For hybrid networking with legacy STP devices and for full interoperability with RSTP-enabled devices, MSTP supports the following work modes: STP-compatible mode, RSTP mode, and MSTP mode.
- In STP-compatible mode, all ports of the device send out STP BPDUs,
- In RSTP mode, all ports of the device send out RSTP BPDUs. If the device detects that it is connected to a legacy STP device, the port connecting to th e legacy STP device will migrate automatically to STP-compatible mode.
- In MSTP mode, all ports of the device send out MSTP BPDUs. If the device detects that it is connected to a legacy STP device, the port connecting to the legacy STP device will migrate automatically to STP-compatible mode.
Make this configuration on the root bridge and on the leaf nodes separately.
To configure the MSTP work mode:
Enter system view and use the command
system-view
Configure the work mode of MSTP
stp mode { stp | rstp | mstp }
CAUTION:
- After configuring a device as the root bridge or a secondary root bridge, you cannot change the priority of the device.
- During root bridge selection, if all devices in a spanning tree have the same priority, the one with the lowest MAC address will be selected as the root bridge of the spanning tree.
Device priority is a factor in spanning tree calculation. The priority of a device determines whether the device can be elected as the root bridge of a spanning tree. A lower numeric value indicates a higher priority. We can set the priority of a device to a low value to specify the device as the root bridge of the spanning tree. A spanning tree device can have different priorities in different MSTIs.
To configure the priority of a device in a specified MSTI follow the steps given below:
Enter system view and use the command
system-view
Configure the priority of the current device in a specified MSTI, use the command
stp [ instance instance-id ] priority priority
By setting the maximum hops of an MST region, the user can restrict the region size. The maximum hops configured on the regional root bridge will be used as the maximum hops of the MST region.
The regional root bridge always sends a configuration BPDUs with a hop count set to the maximum value. When a switch receives this configuration BP DU, it decrements the hop count by 1 and uses the new hop count in the BPDUs it propagates. When the ho p count of a BPDUS reaches 0, it is discarded by the device that received it. Devices beyond the reach of the maximum hop can no longer take part in spanning tree calculation, and the size of the MST region is confined.
To configure the maximum number of hops of an MST region follow the steps given below:
Enter system view and use the command
system-view
Configure the maximum hops of the MST region and use the command
stp max-hops hops
Any two terminal devices in a switched network are interconnected through a specific path composed of a series of devices. The network diameter is the number of devices on the path composed of the most devices. The network diameter is a parameter th at indicates the network size. A bigger network diameter indicates a larger network size.
Make this configuration on the root bridge only.
To configure the network diameter of a switched network follow the steps given below:
Enter system view and use the command
system-view
Configure the network diameter of the switched network, use the command
stp bridge-diameter diameter
STP calculation involves the following timing parameters:
Forward delay - Determines the time interval of state transition. To prevent temporary loops, a port must go through an intermediate state, the learning state, before it transitions from the discarding state to the forwarding state, and must wait a certain period of time (for ward delay) before it transitions from one state to another to keep synchronized with the remote device during state transition.
Hello time - Used to detect link failures. STP sends configuration BPDUs at the interval of hello time. If a device fails to receive configuration BPDUs within the hello time, a new spanning tree calculation process will be triggered because of configuration BPDU timeout.
Max age - Used to detect configuration BPDU timeout. In the CIST, the device determines whether a configuration BPDU received on a port has expired based on the max age timer. If a port receives a configuration BPDU that has expired, that MSTI must be re-calculated. The max age is meaningless for MSTIs.
To avoid frequent network changes, the settings of the hello time, forward delay and max age timers must meet the following formulas:
HP does not recommend us to manually set the spanning tree timers. Instead, we can specify the network diameter and let spanning tree protocols automatically calculate the timers based on the network diameter. If the network diameter uses the default value, the timers also use their default values. Configure the timers on the root bridge only, and the timer settings on the root bridge apply to all devices on the entire switched network.
To configure the spanning tree timers follow the steps given below:
Enter system view and use the command
system-view
Configure the forward delay timer (in STP/RSTP/MSTP mode) and use the command
stp timer forward-delay time
Configure the hello timer
stp timer hello time
Configure the max age timer (in STP/RSTP/MSTP mode) and use the command
stp timer max-age time
The length of the forward delay is related to the network diameter of the switched network. The larger the network diameter is, the longer the forward delay should be. If the forward delay is too short, temporary redundant paths can be introduced. If the forward delay is too long, it may take a long time for the network to converge. HP recommends to use the default setting.
An appropriate hello time enables the device to timely detect link failures on the network without using excessive network resources. If the hello time is set too long, the device will take packet loss as a link failure and trigger a new spanning tree calculation process. If the hello time is set too short, the device will send repeated configuration BPDUs frequently, which adds to the device burden and causes waste of network resources. HP recommends to use the default setting. If the max age time is too short, the network devices will frequently launch spanning tree calculations and may take network congestion as a link failure.
If the max age is too long, the network may fail to timely detect link failures and fail to timely launch spanning tree calculations , reducing the auto-sensing capability of the network. HP recommends to use the default setting.
The timeout factor is a parameter used to decide the timeout time in the following formula:
Timeout time = timeout factor × 3 × hello time.
After the network topology is stabilized, each non-root-bridge device forwards configuration BPDUs to the downstream devices at the interval of hello time to check whether any link is faulty. If a device does not receive a BPDU from the upstream device within nine times the hello time, it assumes that the upstream device has failed and starts a new spanning tree calculation process.
Sometimes a device may fail to receive a BPDU from the upstream device because the upstream device is busy. If a spanning tree calculation occurs, the calculation can fail and also waste the network resources. In a very stable network, avoid such unwanted spanning tree calculations by setting the timeout factor to 5, 6, or 7.
To configure the timeout factor follow the steps given below:
Enter system view and use the command
system-view
Configure the timeout factor of the device and use the command
stp timer-factor factor
The maximum rate of a port refers to the maximum number of BPDUs the port can send within each hello time. The maximum rate of a port is related to the physical status of the port and the network structure.
Make this configuration on the root bridge and on the leaf nodes separately.
To configure the maximum rate of a port or a group of ports follow the steps given below:
Enter system view and use the command
system-view
Enter interface view or port group view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view and use the command
interface interface-type interface-number
Enter port group view and use the command
port-group manual port-group-name
Configure the maximum rate of the ports and use the command
stp transmit-limit limit
The higher the maximum port rate is, the more BPDUs will be sent within each hello time, and the more system resources will be used. By setting an appropriate maximum port rate, the user can limit the rate at which the port sends BPDUs and prevent MSTP from using excessive network resources when the network becomes instable. HP recommends to use the default setting.
If a port directly connects to a user terminal rather than another device or a shared LAN segment, this port is regarded as an edge port. When a network topology change occurs, an edge port will not cause a temporary loop. Because a device does not know whether a port is directly connected to a terminal, the user needs to manually configure the port to be an edge port. After that, this po rt can transition rapidly from the blocked state to the forwarding state without delay.
Make this configuration on the root bridge and on the leaf nodes separately.
To specify a port or a group of ports as edge port or ports follow the steps given below:
Enter system view and use the command
system-view
Enter interface view or port group view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view and use the command
interface interface-type interface-number
Enter port group view and use the command
port-group manual port-group-name
Configure the current ports as edge ports and use the command
stp edged-port enable
With BPDU guard disabled, when a port set as an edge port receives a BPDU from another port, it will become a non-edge port again. To restore the edge port, re-enable it.
If a port directly connects to a user terminal, configure it as an edge port and enable BPDU guard for it. This enables the port to transition to the forwarding state fast while ensuring network security. Otherwise, the port can be blocked and changes to the forwarding state after a period twice the forward delay. In the waiting period, service traffic is interrupted.
Among loop guard, root guard and edge port settings, only one function (whichever is configured the earliest) can take effect on a port at the same time.
CAUTION: If you change the standard that the device uses to calculate the default path costs, you restore the path costs to the default.
Path cost is a parameter related to the rate of a port. On an MSTP-enabled device, a port can have different path costs in different MSTIs. Setting appropriate path costs allows VLAN traffic flows to be forwarded along different physical links, achieving VLAN-based load balancing.
The device can automatically calculate the default path cost; alternatively, the user can also configure the path cost for ports.
Make the following configurations on the leaf nodes only.
Specifying a standard that the device uses when calculating the default path cost:
Specify a standard for the device to use in automatic calculation for the default path cost. The device supports the following standards:
dot1d-1998 - Device calculates the default path cost for ports based on IEEE 802.1d-1998.
dot1t - Device calculates the default path cost for ports based on IEEE 802.1t.
legacy - Device calculates the default path cost for ports based on a private standard.
To specify a standard for the device to use when it calculates the default path cost follow the steps given below:
Enter system view and use the command
system-view
Specify a standard for the device to use when it calculates the default path costs of its ports and use the command
stp pathcost-standard { dot1d- 1998 | dot1t | legacy }
Table 1 - Mappings between the link speed and the path cost, shows the mappings between the link speed and the path cost.
Link Speed
|
Link Speed
|
Path Cost
|
|---|
IEEE 802.1d-1998
|
IEEE 802.1t
|
Private Standard
|
|---|
0
|
-
|
65,535
|
200,000,000
|
65,535
|
10 Mb/s
|
Single Port
|
100
|
2,000,000
|
2000
|
Aggregate interface containing 2 selected ports
|
1,000,000
|
1800
|
Aggregate interface containing 3 selected ports
|
666,666
|
1600
|
Aggregate interface containing 4 selected ports
|
500,000
|
1400
|
100 Mb/s
|
Single Port
|
19
|
200,000
|
200
|
Aggregate interface containing 2 selected ports
|
100,000
|
180
|
Aggregate interface containing 3 selected ports
|
66,666
|
160
|
Aggregate interface containing 4 selected ports
|
50,000
|
140
|
1000 Mb/s
|
Single Port
|
4
|
20,000
|
20
|
Aggregate interface containing 2 selected ports
|
10,000
|
18
|
Aggregate interface containing 3 selected ports
|
6666
|
16
|
Aggregate interface containing 4 selected ports
|
5000
|
14
|
10 Gb/s
|
Single Port
|
2
|
2000
|
2
|
Aggregate interface containing 2 selected ports
|
1000
|
1
|
Aggregate interface containing 3 selected ports
|
666
|
1
|
Aggregate interface containing 4 selected ports
|
500
|
1
|
When calculating path cost for an aggregate interface, IEEE 802.1d-1998 does not take into account the number of selected ports in its aggregation group as IEEE 802.1t does. The calculation formula of IEEE 802.1t is: Path Cost = 200,000,000/link speed (in 100 kb/s), where link speed is the sum of the link speed values of the selected ports in the aggregation group.
To configure the path cost of ports follow the steps given below:
Enter system view and use the command
system-view
Enter interface view or port group view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view and use the command
interface interface-type interfacenumber
Enter port group view and use the command
port-group manual port-groupname
Configure the path cost of the ports
stp [ instance instance-id ] cost cost
When the path cost of a port changes, the system re-calculates the role of the port and initiates a state transition.
Configuration example
# Specify that the device use IEEE 802.1d-1998 to calculate the default path costs of its ports.
<Sysname> system-view
[Sysname] stp pathcost-standard dot1d-1998
# Set the path cost of GigabitEthernet 1/0/3 on MSTI 2 to 200.
<Sysname> system-view
[Sysname] interface gigabitethernet 1/0/3
[Sysname-GigabitEthernet1/0/3] stp instance 2 cost 200
The priority of a port is an important factor in determining whether the port can be elected as the root port of a device. If all other conditions are the same, the port with the highest priority will be elected as the root port. On an MSTP-enabled device, a port can have different priorities in different MSTIs, and the same port can play different roles in different MSTIs, so that data of different VLANs can be propagated along different physical paths, implementing per-VLAN load balancing. The user can set port priority values based on the actual networking requirements.
Make this configuration on the leaf nodes only.
To configure the priority of a port or a group of ports follow the steps given below:
Enter system view and use the command
system-view
Enter interface view or port group view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view and use the command
interface interface-type interfacenumber
Enter port group view and use the command
port-group manual port-group-name
Configure the port priority
stp [ instance instance-id ] port priority priority
When the priority of a port changes, MSTP re-calculates the role of the port and initiates a state transition.
A lower priority value indicates a higher priority. If the user configures the same priority value for all ports on a device, the specific priority of a port depends on the index number of the port. A lower index number means a higher priority. Changing the priority of a port triggers a new spanning tree calculation process.
A point-to-point link is a link directly connecting two devices. If the two ports across a point-to-point link are root ports or designated ports, the ports can rapidly transition to the forwarding state after a proposal-agreement handshake process.
Make this configuration on the root bridge and on the leaf nodes separately.
To configure the link type of a port or a group of ports follow the steps given below:
Enter system view and use the command
system-view
Enter interface view or port group view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view and use the command
interface interface-type interface-number
Enter port group view and use the command
port-group manual portgroup- name
Configure the port link type and use the command
stp point-to-point { auto | force-false | forcetrue }
If the current port is a Layer 2 aggregate interface or if it works in full duplex mode, the user can configure the link to which the current port connects as a point-to-point link. HP recommends to use the default setting, and let MSTP detect the link status automatically.
If a port is configured as connecting to a point-to-point link or a non- point-to-point link, the setting takes effect for the port in all MSTIs.
If the physical link to which the port connects is not a point-to-point link and manually set it to be one, the configuration may cause temporary loops.
A port can receive/send MSTP packets in the following formats:
By default, the packet format recognition mode of a port is auto. The port automatically distinguishes the two MSTP packet formats, and determines the format of packets it will send based on the recognized format. Configure the MSTP packet format on a port. When working in MSTP mode after the configuration, the port sends and receives only MSTP packets of the format the user has configured to communicate with devices that send packets of the same format. Make this configuration on the root bridge and on the leaf nodes separately.
To configure the MSTP packet format to be supported on a port or a group of ports follow the steps given below:
Enter system view and use the command
system-view
Enter interface view or port group view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view and use the command
interface interface-type interfacenumber
Enter port group view and use the command
port-group manual port-group-name
Configure the mode that the port uses to recognize/send MSTP packets and use the command
stp compliance { auto | dot1s | legacy }
MSTP provides the MSTP packet format incompatibility guard function. In MSTP mode, if a port is configured to recognize/send MSTP packets in a mode other than auto, and receives a packet in a format different from the specified type, the port will become a designated port and remain in the discarding state to prevent the occurrence of a loop.
MSTP provides the MSTP packet format frequent change guard function. If a port receives MSTP packets of different formats frequently, the MSTP packet format configuration can contain errors. If the port is working in MSTP mode, it will be disabled for protection. The closed ports can be restored only by the network administrators.
A large-scale, MSTP-enabled network can have many MSTIs, and ports may frequently transition from one state to another. In this situation, the user can enable devices to output the port state transition information of all MSTIs or the specified MSTI so as to monitor the port states in real time.
Make this configuration on the root bridge and on the leaf nodes separately.
To enable output of port state transition information follow the steps given below:
Enter system view and use the command
system-view
Enable output of port state transition information
stp port-log { all | instance instance-id }
The user must enable MSTP for the device before any other MSTP-related configurations can take effect.
Make this configuration on the root bridge and on the leaf nodes separately.
Enabling the spanning tree feature (in STP/RSTP/MSPT mode)
To enable the spanning tree feature in STP/RSTP/MSTP mode follow the steps given below:
Enter system view and use the command
system-view
Enable the spanning tree feature globally
stp enable
Enter interface view or port group view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view and use the command
interface interface-type interface-number
Enter port group view and use the command
port-group manual portgroup- name
Enable the spanning tree feature for the port or group of ports and use the command
stp enable
In system view, the user can use the stp enable or undo stp enable command to enable or disable STP globally. Use the undo stp enable command to disable the MSTP feature for certain ports so that they will not take part in spanning tree calculation to save the CPU resources of the device.
If a port on a device that is running MSTP, RSTP, or PVST connects to an STP device, this port automatically transitions to the STP-compatible mode. However, it cannot automatically transition back to the original mode under the following circumstances:
The STP device is shut down or removed.
The STP device transitions to the MSTP, RSTP, or PVST mode.
Performing mCheck globally
MSTP has three working modes: STP compatible mode, RSTP mode, and MSTP mode.
If a port on a device running MSTP (or RSTP) connects to a device running STP, this port will migrate to the STP-compatible mode automatically. However, it will not be able to migrate automatically back to the MSTP (or RSTP) mode, but will remain working in the STP-compatible mode under the following circumstances:
To perform global mCheck:
Enter system view and use the command
system-view
Perform mCheck and use the command
stp mcheck
Performing mCheck in interface view:
To perform mCheck in interface view:
Enter system view and use the command
system-view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view and use the command
interface interface-type interface-number
Perform mCheck and use the command
stp mcheck
As defined in IEEE 802.1s, interconnected devices are in the same region only when the MST region-related configurations (region name, revision level, VLAN-to-instance mappings) on them are identical. An MSTP-enabled device identifies devices in the same MST region by checking the configuration ID in BPDU packets. The configuration ID includes the region name, revision level, configuration digest that is in 16-byte length and is the result calculated via the HMAC-MD5 algorithm based on VLAN-to-instance mappings.
Since MSTP implementations vary with vendors, the configuration digests calculated using private keys is different. The different vendors’ devices in the same MST region cannot communicate with each other.
Enabling the digest snooping feature on the port connecting the local device to a third-party device in the same MST region can make the two devices communicate with each other.
Before enabling digest snooping, ensure that associated devices of different vendors are connected and run MSTP.
Configuring the digest snooping feature:
The user can enable digest snooping only on a device that is connected to a third-party device that uses its private key to calculate the configuration digest.
To configure digest snooping perform the following:
Enter system view and use the command
system-view
Enter interface or port group view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view and use the command
interface interface-type interface-number
Enter port group view and use the command
port-group manual portgroup- name
Enable digest snooping on the interface or port group
Enable digest snooping on the interface or port group
Return to system view
quit
Enable global digest snooping
stp config-digest-snooping
With the digest snooping feature enabled, comparison of configuration digest is not needed for in-the-same-region check, so the VLAN-to-instance mappings must be the same on associated ports.
With global digest snooping enabled, modification of VLAN-to-instance mappings and removing of the current region configuration using the undo stp region-configuration command are not allowed. The user can only modify the region name and revision level.
The user must enable digest snooping both globally and on associated ports to make it take effect. HP recommends to enable digest snooping on all associated ports first and then globally, making the configuration take effect on all configured ports and reducing impact on the network.
To avoid loops, do not enable digest snooping on MST region edge ports. HP recommends to enable digest snooping first and then MSTP. To avoid traffic interruption, do not configure digest snooping when the network works well.
Digest snooping configuration example:
Network requirements:
As shown in Figure - Digest snooping configuration:
Device A and Device B connect to Device C, which is a third-party device. All these devices are in the same region.
Enable digest snooping on Device A’s and Device B’s ports that connect Device C, so that the three devices can communicate with one another.
Figure 1: Digest snooping configuration

Configuration procedure:
# Enable digest snooping on GigabitEthernet 1/0/1 of Device A and enable global digest snooping on Device A.
<DeviceA> system-view
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] stp config-digest-snooping
[DeviceA-GigabitEthernet1/0/1] quit
[DeviceA] stp config-digest-snooping
# Enable digest snooping on GigabitEthernet 1/0/1 of Device B and en able global digest snooping on Device B.
<DeviceB> system-view
[DeviceB] interface gigabitethernet 1/0/1
[DeviceB-GigabitEthernet1/0/1] stp config-digest-snooping
[DeviceB-GigabitEthernet1/0/1] quit
[DeviceB] stp config-digest-snooping
In RSTP and MSTP, the following types of messages are used for rapid state transition on designated ports:
Both RSTP and MSTP devices can perform rapid transition on a designated port only when the port receives an agreement packet from the downstream device. RSTP and MSTP devices have the following differences:
For MSTP, the downstream device’s root port sends an agreement packet only after it receives an agreement packet from the upstream device.
For RSTP, the downstream device sends an agreement packet regardless of whether an agreement packet from the upstream device is received.
Figure 2 - Rapid state transition of an MSTP designated port, shows the rapid state transition mechanism on MSTP designated ports:
Figure 2: Rapid state transition of an MSTP designated port

Figure 3 - Rapid state transition of an RSTP designated port, below shows rapid state transition of an RSTP designated port:
Figure 3: Rapid state transition of an RSTP designated port

If the upstream device is a third- party device, the rapid state transition implementation may be limited. For example, when the upstream device uses a rapid transition mechanism similar to that of RSTP, and the downstream device adopts MSTP and does not work in RSTP mode, the root port on the downstream device receives no agreement packet from the upstream device and sends no agreement packets to the upstream device. As a result, the de signated port of the upstream device fails to transit rapidly and can only change to the forwarding state after a period twice the forward delay.
The no agreement check feature can be enabled on the downstream device’s port to enable the designated port of the upstream device to transit its state rapidly.
Configuration prerequisites:
Before configuring the no agreement check function, complete the following tasks:
Connect a device is to a third- party upstream device supporting MSTP via a point-to-point link.
Configure the same region name, revision level and VLANs-to-instance mappings on the two devices, assigning them to the same region.
Configuring the no agreement check function:
To make the no agreement check feature take effect, enable it on the root port.
To configure no agreement check:
Enter system view and use the command
system-view
Enter interface or port group view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view and use the command
interface interface-type interface-number
Enter port group view and use the command
port-group manual portgroup- name
Enable no agreement check and use the command
stp no-agreement-check
No agreement check configuration example:
As shown in Figure 4:
Device A connects to Device B, a third-party device that has different MSTP implementation. Both devices are in the same region.
Device B is the regional root bridge, and Device A is the downstream device.
Figure 4: No agreement check configuration

Configuration procedure:
# Enable no agreement check on GigabitEthernet 1/0/1 of Device A.
<DeviceA> system-view
[DeviceA] interface gigabitethernet 1/0/1
[DeviceA-GigabitEthernet1/0/1] stp no-agreement-check
Figure 5 - TC snooping application scenario, shows a TC snooping application scenario. Device A and Device B are both IRF-enabled switches and form an IRF virtual device; they operate at the distribution layer and do not have STP enabled. The IRF virtual device formed by Device A and Device B connect to multiple access-layer customer networks, such as Customer 1 and Customer 2. Device C, Device D, and Device E in customer network Customer 1 are all enabled with STP. Customer 1 is dual-uplinked to the IRF virtual device for high availability. The IRF virtual device transparently transmits STP BPDUs from Customer 1 at Layer 2. Other customer networks (such as Custom er 2) act the same as Customer 1.
Figure 5: TC snooping application scenario

In the network, the IRF virtual device transparently transmits the received STP BPDUs and does not participate in STP calculations. When a topology change occurs to the IRF virtual device or attached access-layer networks, the IRF virtual device may need a long time to learn the correct MAC address table entries and ARP entries, resulting in long network disruption. To avoid the network disruption, TC snooping can be enabled on the IRF virtual device.
TC snooping enables a device to actively clear the MAC address table entries and ARP entries upon receiving TC-BPDUs and to re-learn the MAC address table entries and ARP entries, so that the device can normally forward the user traffic.
Configuration prerequisites:
Disable STP globally.
Configuring TC snooping:
Perform the TC snooping configuration on the IRF virtual device shown in Figure 5 - TC snooping application scenario:
To configure TC snooping:
Enter system view
system-view
Enable TC snooping
stp tc-snooping
TC snooping and STP are mutually exclusive.
TC snooping does not take effect on the ports on which BPDU tunneling is enabled for STP.
A spanning tree device supports the following protection functions:
BPDU guard
Root guard
Loop guard
TC-BPDU guard
Configuration prerequisites:
MSTP has been correctly configured on the device.
Enabling BPDU guard
For access layer devices, the access ports can directly connect to the user terminals (such as PCs) or file servers. The access ports are configured as edge ports to allow rapid transition. When these ports receive configuration BPDUs, the system will set these ports automatically as non-edge ports and start a new spanning tree calculation proc ess. This will cause a change of network topology. Under normal conditions, these ports should not receive configuration BPDUs. However, if someone forges configuration BPDUs maliciously to attack the devices, the network will become instable.
MSTP provides the BPDU guard function to protect the system against such attacks. With the BPDU guard function enabled on the devices, when edge ports receive configuration BPDUs, MSTP will close these ports and notify the NMS that these ports have been closed by MSTP. The closed ports will be re-activated by the device after a detection interval.
Make this configuration on a device with edge ports configured.
To enable BPDU guard:
Enter system view and use the command
system-view
Enable the BPDU guard function for the device
stp bpdu-protection
BPDU guard does not take effect on loopback test-enabled ports.
Enabling root guard
The root bridge and secondary root bridge of a spanning tree should be located in the same MST region. Especially for the CIST, the root bridge and secondary root bridge are put in a high-bandwidth core region during network design. However, because of possible configuration errors or malicious attacks in the network, the legal root bridge may receive a configuration BPDU with a higher priority. The current legal root bridge will be superseded by another device, causing an undesired change of the network topology. As a result, the traffic that should go over high-speed links is switched to low-speed links, resulting in network congestion.
To prevent this situation from happening, MSTP provides the root guard function. If the root guard function is enabled on a port of a root bridge, this port will keep playing the ro le of designated port on all MSTIs. Once this port receives a configuration BPDU with a higher priority from an MSTI, it immediately sets that port to the listening state in the MSTI, without forwarding the packet (this is equivalent to disconnecting the link connected to this port in the MSTI). If the port receives no BPDUs with a higher priority within twice the forwarding delay, it will revert to its original state. Make this configuration on a designated port.
To enable root guard:
Enter system view and use the command
system-view
Enter interface view or port group view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view
interface interface-type interface-number
Enter port group view
port-group manual portgroup- name
Enable the root guard function for the ports
stp root-protection
Among loop guard, root guard and edge port settings, only one function (whichever is configured the earliest) can take effect on a port at the same time.
Enabling loop guard
By keeping receiving BPDUs from the upstream device, a device can maintain the state of the root port and blocked ports. However, because of link congestion or unidirectional link failures, these ports may fail to receive BPDUs from the upstream devices. The device will reselect the port roles: Those ports in forwarding state that failed to receive upstream BPDUs will become designated ports, and the blocked ports will transition to the forwarding state, resulting in loops in the switched network. The loop guard function can suppress the occurrence of such loops.
The initial state of a loop guard-enabled port is discarding in every MSTI. When the port receives BPDUs, its state transitions normally; otherwise, it stays in the discarding state to prevent temporary loops.
Make this configuration on the root port and alternate ports of a device.
To enable loop guard:
Enter system view and use the command
system-view
Enter interface view or port group view
Enter Layer 2 Ethernet interface view or Layer 2 aggregate interface view
interface interface-type interface-number
Enter port group view
port-group manual portgroup- name
Enable the loop guard function for the ports
stp loop-protection
Do not enable loop guard on a port connecting user terminals. Otherwise, the port will stay in the discarding state in all MSTIs because it cannot receive BPDUs. Among loop guard, root guard and edge port settings, only one function (whichever is configured the earliest) can take effect on a port at the same time.
Enabling TC-BPDU guard
When receiving TC BPDUs (the BPDUs used to notify topology changes), a switch flushes its forwarding address entries. If someone forges TC-BPDUs to attack the switch, the switch will receive a large number of TC-BPDUs within a short time and be busy with forwarding address entry flushing. This affects network stability.
With the TC-BPDU guard function, the user can set the maximum number of immediate forwarding address entry flushes that the switch can perform within a certain period of time after receiving the first TC-BPDU. For TC-BPDUs received in excess of the limit, the switch performs forwarding address entry flush only when the time period expires. This prevents frequent flushing of forwarding address entries.
To enable TC-BPDU guard:
Enter system view and use the command
system-view
Enable the TC-BPDU guard function
stp tc-protection enable
Configure the maximum number of forwarding address entry flushes that the device can perform every 10 seconds
stp tc-protection threshold number
Read More ...